こちらから、PDF版もダウンロードできます。
1 インストール
すでにインストールしている人は2ワークスペース作成から始めてください。
1.1 無償トライアルの申込
MENOUのホームページ (https://menou.co.jp) にアクセスします。

メニューから「AI開発プラットフォーム」をクリックし、無償トライアルというボタンを押します。


フォームが表示されますので、必要事項を記入して送信!
自動BOTを排除するためのCAPCHAなどありますが、ご協力お願いします。
トライアルの申込が完了しましたら、メールでライセンスのご連絡が届きますので、少しお待ちください。
1.2 ダウンロード
メールでリンクが送られてきたら、利用規約をお読みの上、検査AI開発ツール「MENOU-TE」のダウンロードボタンを押します。

クリックすると、ほどなくダウンロードが開始され、ダウンロードフォルダにMENOU.Menou-TE.〇〇〇〇〇〇〇.msixbundle みたいなファイル名のファイルが出来ています(○○部分にはバージョン名などが含まれます)。
こちらをダブルクリックすると、インストールが開始されます。
インストールはほどなく完了しますので、新しくできたアイコンをダブルクリックし、起動します。アイコンが見つからない場合、Windowsの虫眼鏡
みると、検索結果に表れるはずです。
1.3 初回起動
MENOU-TEを初めて起動したときや、バージョンアップ後の起動時には、アップデートが必要となることがあります。指示にしたがって、最新の状態へとパッケージを更新します。
2 ワークスペースの作成
「ワークスペース」とは、AI検査を開発し実行するまでに必要なデータを保管する場所です。AI検査の開発には「元の画像」が必要ですが、これを元に「アノテーションされた画像」も必要です。さらに、「タスクコネクション(処理の流れ)」を指示することで「学習した結果」も得られます。

2.1 新規ワークスペース
左上のワークスペースボタンをクリックします。

すると、ワークスペースの選択、または新規作成を選ぶポップアップが出ます。
右側の「新しいワークスペースの作成」欄にワークスペース名と作成場所を指定して「作成」ボタンをクリックしましょう。
すると、ワークスペースボタンが指定したワークスペース名に変わり、ワークスペースが作成されました。
2.2 新規データセット
ワークスペースが作成されると、データセットを作成します。
「データセット」とは、AIで用いる画像データ群を指します。学習するデータを複数分けたいときには複数作成しますが、慣れるまでは1つのワークスペースに1つのデータセットがあれば十分です。

新規のワークスペースを作成すると「新しいデータセットの作成」という画面になります。
新しくデータセットを作成する場合、データセット名を入力し、「作成」ボタンをクリックします。
作成されると、画像ファイルを指定する画面に変わります。

2.3 画像インポート
ここで、AI検査を行いたい画像をMENOU-TEにインポートします。「フォルダを選択」してもよいですが、複数選択してドラッグするのが簡単です。
こちらのリンクから、使用する画像をダウンロードしてください。ZIPファイルで圧縮していますので、適宜解凍してお使いください。
最初は20枚ほどのデータがあれば十分です。AIの精度を見ながら、追加のデータを取得すればよいのがMENOU-TEの良いところなので、ある程度の画像があればスタートできます。
ファイルをインポートすると、サムネイルが表示されます。

今回のサンプルでは、MENOUのロゴ画像を用います。

こちらは正常品。
ファイル名はGOODから始まります。

そして、こちらは右上にちょっとした異物に見立てた「染み」があります。
異物はどこにあるかわかりませんから、いろんなところにあります。

ファイル名にBADをあらかじめ付けてあります。
このようにファイル名をあらかじめ付けておくと、どれが不良品なのかファイルを開かなくてもわかります。
画像データのインポートが出来ましたら、プロジェクトを作成します。
2.4 プロジェクトの作成
「プロジェクト」というのは、画像データから作成するAIを指します。プロジェクトの作成ボタンをクリックすると、「新しいプロジェクトの作成」という画面になります。

後から変えられますが、プロジェクトには3つの種類があります。
- 領域検出
セグメンテーションとも呼びます。画像の中にある、特定の特徴を持つ「領域」を検出するAIをつくることができます。 - 分類
画像を分類するようなAIをつくります。良品と不良品を単純に分けるときや、検査品目を分類し、仕分けるAIをつくることができます。 - 異常領域検出
別名「教師なし学習」です。良品のみを学習させ、著しく異常な画像を検出するAIをつくることができます。
これらの3つの種類は、この後説明する「タスクコネクション」で組み合わせることができます。
今回のロゴのサンプルでは、まず「領域検出」で異物を発見することを行ってみます。
「領域検出」をクリックすると、「目的のタスクからプロジェクトを作成する」という画面になりますので、そのまま「作成」ボタンを押します。

すると、このようにタスクコネクションの初期画面になります。
フローチャートを見ると、「入力画面」が「領域検出_0」というタスクにつながっている様子がわかります。
ここまでで、AIモデル作成の準備ができました。
いよいよAIにデータを学習させ、推論できるようなモデルをつくるステップに進みます。
3 アノテーション
「アノテーション」とは、別名ラベリングとか教示と呼ばれている作業です。簡単に言えば、AIに正解を教える作業です。今回の領域検出では、不具合となる異物領域をマーキングすることでアノテーションを行います。
3.1 領域検出のアノテーション
アノテーションを行う前に、AIタスクの名称を分かりやすくします。右側のタスク詳細の、「領域検出_0」と書かれた部分をクリックすると、タスク名を変更するポップアップが表示されます。
ここで、「異物発見」などと記載しておくことで、今後領域検出を複数作成しても混乱を減らせます。
タスク名を変えたら、タスクコネクション ウィンドウ内の領域検出タスクである「異物発見」をクリックします。

すると、画面が切り替わり、学習させる元画像が表示されます。

3.2 アノテーションを行う画像を選ぶ
インポートした画像の一覧が左側のデータプレビューに表示されています。
これらの画像すべてを学習の対象にしてもよいのですが、AIの精度を確認するため、一部だけを学習させ、残りの画像はAIの精度評価用とします。
今回は、GOOD01.png ~ GOOD07.pngは良品として学習させ、BAD_shape1.png ~ BAD_shape7.pngは異物が存在する不具合品として学習させることにします。
3.3 良品のアノテーション(領域検出)##
データプレビューからGOOD01.pngをクリックすると、拡大された画像が中央に表示されます。
この画像は良品ですから、マークさせる部分はありません。なので、左上の「不明」と表示されているところをクリックし、「検出なし」を選びます。
また、この画像は学習に利用するため、「学習フラグ」もクリックし、チェックマークを付けます。

同じことをGOOD02.png ~ GOOD07.pngまで繰り返します。
データプレビュー画面からファイルを複数選択し、右クリックを行うことでもまとめて学習フラグや検出状態の変更はできます。慣れてきたら、まとめて作業すると効率的なアノテーションができるようになります。
3.4 不具合品のアノテーション(領域検出)##
次に不具合の領域をマーキングします。BAD_shape1.pngをプレビューから選び、メイン画面に表示させます。すると、ロゴの左上部分が変な形になっているのが分かります。この飛び出た部分をマーキングし、AIに教えることをします。

拡大・縮小
精度の高いAIをつくるには、アノテーションの精度は大事です。したがって、画像を拡大してマーキングします。Ctrlキーを押しながら、マウスのホイールを回すと、拡大・縮小が自在に行えます。また、右上の虫メガネをクリックすることでも拡大・縮小は可能です。
ペンサイズ

細かい部分は細いペンで、太い部分は太いペンでマーキングすると早いです。
ペン幅のピクセル表示を見ながら、調節します。Shiftキーを押しながらマウスホイールを回すことでも、ペンサイズを変えることができます。
消しゴム
マーキングが大きくなったり、はみ出してしまった場合は、消しゴムで消すことができます。消しゴムアイコンをクリックすることでツールが切り替わり、ペンと同様に消すことができます。もちろん、Ctrl+Zによる「戻る」もできます。
画像のマーキングが終わったら、良品の画像と同様に、検出状態を設定します。

良品のときは「検出なし」としましたが、今回は「検出あり」を選びます。また、学習に使いますので、学習フラグにはチェックを入れます。
続けてBAD_shape2.pngをマーキングします。
今回は、ピクセルごとペンで塗らずに、もう少し効率的に「自動選択」ペンを用いましょう。
こちらの、マジックワンドアイコンを選びます。
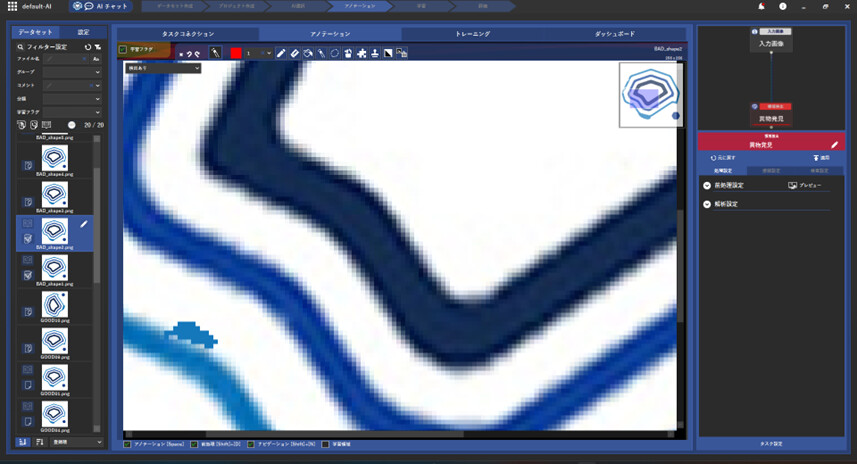
そして、異物にカーソルを置いてクリックすると・・・・

なんと!自動的に色塗りしてくれました。
この自動選択はもちろんあまり高度なAIではないので、複雑な形状には適していません。検出が易しいものについて自動的にマーキングしてくれる簡易ツールとして活用するのがいいです。
一瞬でマーキングしましたが、検出状態の設定と学習フラグのチェックを忘れずに行い、この画像のアノテーションを完了させます。
同様に BAD_shape7.pngまでのアノテーションを行えば、いよいよ学習(トレーニング)ができるようになります。
4 学習(トレーニング)
「トレーニング」というタブをクリックすると、AIモデルを学習することができます。
アノテーションされた画像からAIが共通の特徴を抽出し、他の画像を判別するための計算を行います。このステップは、GPU搭載されたパソコンを用いない場合は、非常に時間がかかったり、計算に失敗することがありますので、推奨されたスペックのパソコンを使ってください。

3.5 トレーニングオプション
アノテーションが終わっていれば、自動ですべての計算ができますが、少しだけ設定オプションがあります。

画面の下部に様々なオプションが表示されるので、今回は「全てをOFF」をクリックしておきます。画像枚数が少ない場合は、デフォルトの初期値を用いるのが一般的ですが、今回は特別にオフにします。(回転、コントラスト、明るさ、反転、ノイズ、倍率、歪みなどは、元画像を割り増しする条件を示しています。)
3.6 学習開始
学習を開始するには、![]() 右向きの三角形のボタンを押します。
右向きの三角形のボタンを押します。

指定した学習エポック数(1000回)の計算に10分くらいはかかります(GPUは3070Tiを使用)。
AIが学習している間も、エラーが減る様子がグラフで表示されますし、残り時間も常に表示されているので、コーヒーでも飲みながら少し待ちます。

学習が終了すると、GPUのファンが少し静かになり、ダッシュボード画面に移行し、さっそく結果を確認しましょう。

5 結果の確認と修正

ダッシュボード画面が表示されると、真ん中に100%の数字が2つ見えます。これは、見事に精度が出せたことを示していますが、同時に「不明」という欄があるのが分かります。
アノテーションを行っていない画像については、AIは正解を知らないため、不明のままで表示しているのです。
ちなみに、この表はコンフュージョン・マトリクス (混合行列)と呼ばれていて、AIの評価に欠かせない表になっています。
3.7 ヒートマップの確認
それでは、アノテーションを行っていないBAD_shape10.pngを選んで表示してみましょう。すると、見事に異物を赤く推論していることが分かります。

左上を見ると、検出領域は2つあり、スコアは1.00となっています。つまり、100%確信しているということです。
この検出状態を「検出あり」に指定してあげることで、AIはやっぱり正しかったということがコンフュージョン・マトリクスにも反映されます。
アノテーションを行っていない他の画像についても、同様に「検出あり」「検出なし」と適当に設定することで、精度が100%のまま、不明はゼロになります。

この状態になれば、一通り異物を検出することのできるAIが出来たと言えるでしょう。
もしも結果がこの通りでなくても心配しないでください。アノテーションの条件を変えれば結果も変わり得ます。また、AIが画像から学ぼうとする際に、少し「偶然」の力を借りることがあるというのも原因です。人間がパズルのピースを探す際、たまたま手にとったピースを当てはめてみるように、偶然によって結果が多少変化します。この偶然によるバラツキを減らすためにも何1000回もの学習エポックを繰り返すのです。
例えば、似たような条件でトレーニングをやり直した場合、このような結果になりました。

コンフュージョン・マトリクスを見ると、1つの画像で検出されるべき異物が検出されていないことが分かります。
次にこの精度を高める方法についてご紹介します。
3.8 モデルの分析(スコアヒストグラム)
精度以外に一つだけ確認しておいた方がいいことがあります。結果のダッシュボード画面右側にある「スコアヒストグラム」です。
このヒストグラムは、AIがどれだけ、「検出あり」と「検出なし」を区切ることができたのかを数値で表しています。横軸は、左端が0、右端が1.0というスコアを示しています。つまり、先ほど説明したスコアの分布となっています。

1回目

2回目
AIにとってまったく「検出なし」と言える0に緑のとがった山があり、AIが自信をもって「検出あり」と言い切れる1.0に赤いとがった山があるのが理想的です。ただし、現実の検査では、人間も迷うような検査もありますので、赤と緑の山のすそ野が近くなることも珍しくありません。極力「検出あり」と「検出なし」の距離を取れると安定した検査になります。
2つの山が重なっていると、精度にバラつきが出てしまいます。
また、この画面の「閾値」を変えることで、何をもって「検出なし」とするか、「検出あり」とするかの境目を変更することができます。デフォルト値の0.5より小さくすることで、疑わしきは罰し(「検出あり」にする)、右の大きい値にすることで、疑わしきは罰しない(「検出なし」にする)ことになります。
今回の例では、「検出なし」はばっちり。「検出あり」については、少しスコアが低いものもあることがわかります。
2回目の結果では、閾値0.5では誤検出が発生していることを表しています。
このようなケースでは、閾値を例えば0.25に下げることで、このように精度を100%にすることができました。

3.9 モデルの改善
閾値を変更するだけでは改善できる幅は限られています。最終的な調整と考えてください。
もう一つ、簡単な調整方法をご紹介します。
それは、学習エポック数を増やすことです。

先ほど1000回の繰り返しでAIが答えを探していたのに対し、5000回やってみましょう。
人間はボタンを押すだけですが、計算時間はそのまま5倍かかるので、約50分かかってしまいます。

そして時間をかけたら、ご覧の通り、スコアがまとまってきました。
エポック数を増やし、AIが画像群の特徴を見出す回数を増やすことで、精度を向上させることができます。
詳しくは今後のチュートリアルでご説明しますが、できればさほどエポック数をかけずにスコアを0や1に近づけていくことが、より安定したAIになります。
具体的には:
- 不具合品の限界的な画像を学習させる
つまり、ギリギリNGになるようなものを学習させることです - さまざまなケースの不具合画像を学習させる
- 色んな不具合を学ばせると、AIは不具合に詳しくなります
- アノテーションを見直す
- 学習画像数を増やす
といった改善策が挙げられます。
これらの改善方法については、中級編にてご紹介します。